2020. 11. 20. 05:00ㆍPython과 머신러닝/웹 데이터 추출
요약
- XML이란 eXtensible Markup Language의 약자로 데이터의 구조와 의미를 설명하기 위해 Tag(Markup)를 사용하는 언어이다.
- HTML과 비슷하게 데이터가 정형화되어 있어 분석이 편리하고, 이를 더욱 쉽게 Parsing 하는 BeautifulSoup을 사용해보려 한다.
- 2020/11/13 - [Python과 머신러닝/웹 데이터 추출] - [Python.Web] 정규표현식을 이용한 웹 데이터 파싱 - urllib, regular expression
- 2020/11/17 - [Python과 머신러닝/웹 데이터 추출] - [Python.Web] wget으로 웹 데이터 다운로드 및 파싱 - wget.download
- 2020/11/18 - [Python과 머신러닝/웹 데이터 추출] - [Python.Web] 실시간 금융 데이터 파싱하기 추출
[Python.Web] 정규표현식을 이용한 웹 데이터 파싱 - urllib, regular expression
웹사이트에서 원하는 형태의 데이터를 긁어오는 방법을 알아보자. 0. 요약 1. 원하는 URL을 정한다. 2. URL로부터 모든 text를 string으로 읽어온다. 3. 내가 찾고자 하는 string을 regular expression 형태로
coding-grandpa.tistory.com
[Python.Web] wget으로 웹 데이터 다운로드 및 파싱 - wget.download
요약 한 웹사이트에서 여러 가지의 파일을 다운로드하고 싶을 때에, wget을 사용하여 한번에 다운 받는 프로그램을 짤 수 있다 이전에 정리한 내용에 이어서, 정규식을 사용하여 원하는 파일을
coding-grandpa.tistory.com
[Python.Web] 실시간 금융 데이터 파싱하기 추출
요약 URL로부터 정보를 뽑아오는 3번째 예제이다 (앞의 예제를 못 봤다면 참고해야 이해가 될 것이다) Python으로 웹사이트에서 데이터 추출하기 (urllib, regular expression) 웹사이트에서 원하는 형태의
coding-grandpa.tistory.com
1. XML에 대하여
- XML은 eXtensible Markup Language의 약자이다.
- 데이터의 구조와 의미를 설명하기 위해 Tag(Markup)를 사용하는 언어이다.
- HTML과 문법이 비슷하여 데이터 저장 방식의 대표 Legacy(?) 언어가 되었다.
- 정보의 구조에 대한 정보인 스키마와 DTD 등으로 정보에 대한 정보(Metadata)가 표현되며
- 용도에 따라 다양한 형태로 변경이 가능하다.
- 쉽게 말해, 컴퓨터에 정보를 주고 받기 위해 매우 유용한 저장 방식이다.
- 예를 하나 보자 (출처 : w3schools)
<breakfast_menu>
<food>
<name>Belgian Waffles</name>
<price>$5.95</price>
<description>Two of our famous Belgian Waffles with plenty of real maple syrup</description>
<calories>650</calories>
</food>
<food>
<name>Strawberry Belgian Waffles</name>
<price>$7.95</price>
<description>Light Belgian waffles covered with strawberries and whipped cream</description>
<calories>900</calories>
</food>
<food>
<name>Berry-Berry Belgian Waffles</name>
<price>$8.95</price>
<description>Light Belgian waffles covered with an assortment of fresh berries and whipped cream</description>
<calories>900</calories>
</food>
<food>
<name>French Toast</name>
<price>$4.50</price>
<description>Thick slices made from our homemade sourdough bread</description>
<calories>600</calories>
</food>
<food>
<name>Homestyle Breakfast</name>
<price>$6.95</price>
<description>Two eggs, bacon or sausage, toast, and our ever-popular hash browns</description>
<calories>950</calories>
</food>
</breakfast_menu>
2. XML과 BeautifulSoup은 무슨 관계일까
- XML은 Tree 구조로 데이터가 정리되기 때문에 아주 정형화되어 있다는 인상을 받는다.
- 정규식을 공부했다면 정규식을 짜서 필요한 정보를 추출하고 싶겠지만, 이를 쉽게 해주는 parser tool들이 많다.
- 오늘은 그중 대표 격인 BeautifulSoup을 사용할 예정이다.
- BeautifulSoup이란
- HTML, XML 등 Markup 언어 Scraping을 위한 대표적인 Tool이다.
- LXML과 Html5lib 등의 parser를 사용하고
- 속도는 썩 좋지 않다 (그래도 일반적인 분석에는 큰 지장이 없어 많이들 사용한다)
3. Beautiful Soup 설치
- Anaconda 설치
- cmd창을 열어서 conda --version을 했을 경우 error가 난다면 Anaconda가 없으니, anaconda부터 설치가 필요하다. 이 링크에서 다운로드하면 된다.
Anaconda | Individual Edition
Anaconda's open-source Individual Edition is the easiest way to perform Python/R data science and machine learning on a single machine.
www.anaconda.com
- 가상 환경 생성 및 활성화
- conda create -n ml은 ml이라는 이름의 가상 환경을 생성하겠다는 의미이다
- 해당 가상 환경에서 사용할 python의 버전은 3.7로 지정한다.
- activate는 활성화를 시켜서 생성된 가상환경에 진입하는 코드이다
- 이 코드는 모두 cmd 창에서 실행한다.
conda create -n ml python=3.7 # 가상환경 생성
conda activate ml # 가상환경 활성화- 가상환경 내에 설치 필요한 것들 진행
- 가상환경에 진입했다면, 다음 코드를 한 줄씩 cmd에서 수행하여 설치해준다
conda install lxml
conda install -c anaconda beautifulsoup4
4. BeautifulSoup을 통한 Parsing 및 데이터 추출
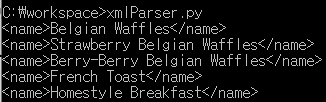
- XML 파일을 파일로 읽어서 BeautifulSoup에게 전달해주면, find 혹은 find_all 등의 함수를 통해서 원하는 값만 추출할 수 있다.
from bs4 import BeautifulSoup # BeautifulSoup을 불러온다
file = open('menu.xml', "r") #xml 파일을 읽어서
Soup = BeautifulSoup(file, "lxml") #BeautifulSoup을 생성할 때 전달한다.
names_list = Soup.find_all("name") # BeautifulSoup 객체를 통해 찾고 싶은 Tag를 전부 찾을 수 있다.
for name in names_list: # 메뉴명을 하나씩 출력한다. 이렇게 쉬워도 되는건가 싶다.
print(name)
마무리
- Anaconda의 가상 환경에 BeautifulSoup을 깔아놓으면 XML/HTML 등 Markup Language를 분석하고 추출하고 너무 쉽다.
- 너무 쉬워서 '나는 개발자로 뭘 해야 되지?'라는 의문이 생길 정도이다.
- 하지만 데이터를 쉽게 추출해서 모은 뒤, 더 의미 있고 가치 있는 데이터 간의 연결고리를 찾는 게 우리의 미래를 보장할 것 같다.
- 2020/11/23 - [Python과 머신러닝/웹 데이터 추출] - [Python.Web] BeautifulSoup과 wget 으로 웹크롤링, 데이터 스크레이핑
[Python.Web] BeautifulSoup과 wget 으로 웹크롤링, 데이터 스크레이핑
요약 지난 내용은 다운로드하여놓은 xml파일을 분석했다면, 이번엔 웹에서 다운로드하는 단계까지 자동화한다 BeautifulSoup으로 하는 웹크롤링, 데이터 스크레이핑 요약 XML이란 eXtensible Markup Languag
coding-grandpa.tistory.com
'Python과 머신러닝 > 웹 데이터 추출' 카테고리의 다른 글
| [Python.JSON] Python으로 JSON 데이터 파싱 - 이론편 (0) | 2020.11.24 |
|---|---|
| [Python.Web] BeautifulSoup과 wget 으로 웹크롤링, 데이터 스크레이핑 (0) | 2020.11.23 |
| [Python.Web] 실시간 금융 데이터 파싱하기 추출 (0) | 2020.11.18 |
| [Python.Web] wget으로 웹 데이터 다운로드 및 파싱 - wget.download (0) | 2020.11.17 |
| [Python.Web] 정규표현식을 이용한 웹 데이터 파싱 - urllib, regular expression (0) | 2020.11.13 |