[Python.Pandas] Groupby 함수 이해하기 - 1편
2020. 12. 23. 05:00ㆍPython과 머신러닝/Pandas 데이터 분석
1. Groupby 란?
- GroupBy란, 주어진 데이터를 그룹 별로 구분하여 데이터를 보기 위해 사용되는 함수이다.
- SQL을 해본 사람이라면 SQL의 Groupby와 동일한 동작을 하는 함수이다.
- Excel의 Pivot Table과도 유사한 기능이라고 이해하면 쉽다.
- 다음 그림을 보면 조금 더 직관적으로 이해될 것이다.
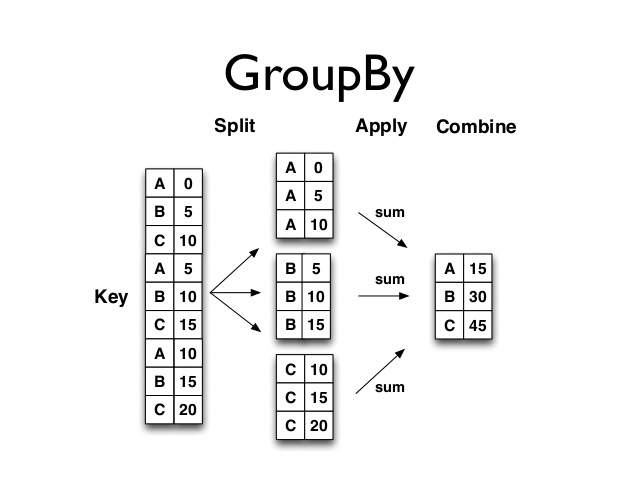
2. GroupBy 사용 예시
In [1]:import pandas as pd
In [2]:ipl_data ={'Team':['Riders', 'Riders', 'Devils', 'Devils', 'Kings', 'Kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'],
'Rank':[1,2,2,3,3,4,1,1,2,4,1,2],
'Year':[2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017],
'Points':[879,789,863,673,741,812,756,788,694,701,804,690] }
df = pd.DataFrame(ipl_data)
df
Out[2]:
Team Rank Year Points
0 Riders 1 2014 879
1 Riders 2 2015 789
2 Devils 2 2014 863
3 Devils 3 2015 673
4 Kings 3 2014 741
5 Kings 4 2015 812
6 Kings 1 2016 756
7 Kings 1 2017 788
8 Riders 2 2016 694
9 Royals 4 2014 701
10 Royals 1 2015 804
11 Riders 2 2017 690
In [3]:df.groupby('Team')['Points'].sum() #Team별 Points의 합계
Out[3]:Team
Devils 1536
Kings 3097
Riders 3052
Royals 1505
Name: Points, dtype: int64- In[2]를 통해서 데이터를 입력했다. 실제로는 이런 식으로 데이터를 입력하기보다는 csv를 읽어올 테니 이 과정은 크게 중요하지 않은 예시 데이터의 입력 정도로 이해하면 되겠다.
- In[3] : df.groupby('Team')['Points'].sum() => df를 Team별로 묶은 뒤, 각 팀별 Points를 합계해서 출력하라는 command이고, 이에 따른 결과를 Out[3]에서 확인할 수 있다.
3. Hierarchical Groupby (2개 기준으로 Groupby 하기)
In [4]:h_index = df.groupby(['Team', 'Year'])['Points'].sum()
h_index
Out[4]:Team Year
Devils 2014 863
2015 673
Kings 2014 741
2015 812
2016 756
2017 788
Riders 2014 879
2015 789
2016 694
2017 690
Royals 2014 701
2015 804
Name: Points, dtype: int64
In [5]:h_index['Devils':'Kings']
Out[5]:Team Year
Devils 2014 863
2015 673
Kings 2014 741
2015 812
2016 756
2017 788
Name: Points, dtype: int64
In [6]:type(h_index)
Out[6]:pandas.core.series.Series
In [7]:h_index.index #index가 두개인 (Tuple 형태인) Series 데이터로 출력
Out[7]:MultiIndex([('Devils', 2014),
('Devils', 2015),
( 'Kings', 2014),
( 'Kings', 2015),
( 'Kings', 2016),
( 'Kings', 2017),
('Riders', 2014),
('Riders', 2015),
('Riders', 2016),
('Riders', 2017),
('Royals', 2014),
('Royals', 2015)],
names=['Team', 'Year'])
- In[4] : GroupBy를 Team 별로 하는 것에 더해 연도별로 보고 싶다면 Parameter를 List 형태로 여러 개 전달하면,
- Out[4]와 같이 팀별 연도별 점수 합산을 낼 수 있다.
- In[5] 와 같이 Slicing을 하여 원하는 팀에 대한 정보만 볼 수도 있다.
- 이러한 Groupby의 결과물은 Series 타입이고, 두 개 Group으로 GroupBy가 된 결과물의 index는 Multi Index로 나온다.
- Out[7]에서 보다시피, 해 예제에서는 Team/연도별이기 때문에 2개의 요소를 가진 Tuple의 list가 반환된다.
4. Hierarchical Groupby의 .unstack 과 .stack
In [8]:h_index.unstack() # 행열로 풀어서 보는 방식
Out[8]:
Year 2014 2015 2016 2017
Team
Devils 863.0 673.0 NaN NaN
Kings 741.0 812.0 756.0 788.0
Riders 879.0 789.0 694.0 690.0
Royals 701.0 804.0 NaN NaN
In [9]:h_index.unstack().stack().unstack()
Out[9]:
Year 2014 2015 2016 2017
Team
Devils 863.0 673.0 NaN NaN
Kings 741.0 812.0 756.0 788.0
Riders 879.0 789.0 694.0 690.0
Royals 701.0 804.0 NaN NaN- 두 개의 기준으로 GroupBy를 했다면 unstack을 꼭 알아두자.
- Groupby가 기존 데이터를 Grouping 정도만 수행한 데이터라면, .unstack은 각 기준을 행/열로 풀어서 보여주는 함수이다.
- 그래서 훨씬 더 간소하게 데이터를 정리하고, 보는 입장에서도 서로 비교가 수월해서 자주 사용되는 함수이다.
- 다시 .stack을 하면 기존 데이터로 돌아오니 .stack과 .unstack을 한 쌍으로 같이 기억해두는 것이 유용할 듯하다.
5. 다음 포스트
- 2020/12/24 - [Python과 머신러닝/Pandas 데이터 분석] - [Python.Pandas] Groupby 이해하기 - 2편
- 2020/12/27 - [Python과 머신러닝/Pandas 데이터 분석] - [Python.Pandas] Groupby 실습 / 데이터 분석 (Date/Time 데이터 분석)
[Python.Pandas] Groupby 이해하기 - 2편
0. 이전 포스트 2020/12/23 - [Python과 머신러닝/Pandas 데이터 분석] - [Python.Pandas] Groupby 함수 이해하기 - 1편 [Python.Pandas] Groupby 함수 이해하기 - 1편 1. Groupby 란? GroupBy란, 주어진 데이터를..
coding-grandpa.tistory.com
[Python.Pandas] Groupby 실습 / 데이터 분석 (Date/Time 데이터 분석)
0. 이전 글 Groupby와 관련한 기초는 이전 포스트에 정리하여, 해 포스트보다 더 기본부터 보고 싶다면 아래 글들을 읽는 것도 좋다. 2020/11/17 - [Python과 머신러닝/웹 데이터 추출] - [Python.Web] wget으로
coding-grandpa.tistory.com
'Python과 머신러닝 > Pandas 데이터 분석' 카테고리의 다른 글
| [Python.Pandas] Groupby 실습 / 데이터 분석 (Date/Time 데이터 분석) (0) | 2020.12.27 |
|---|---|
| [Python.Pandas] Groupby 이해하기 - 2편 (0) | 2020.12.24 |
| [Python.Pandas] Built-in Function 이해하기 - .describe() (0) | 2020.12.22 |
| [Python.Pandas] DataFrame.apply, DataFrame.applymap (0) | 2020.12.21 |
| [Python.Pandas] Map 함수 실전편 + .replace함수 사용하기 (0) | 2020.12.20 |