2020. 12. 27. 05:00ㆍPython과 머신러닝/Pandas 데이터 분석
0. 이전 글
- Groupby와 관련한 기초는 이전 포스트에 정리하여, 해 포스트보다 더 기본부터 보고 싶다면 아래 글들을 읽는 것도 좋다.
- 2020/11/17 - [Python과 머신러닝/웹 데이터 추출] - [Python.Web] wget으로 웹 데이터 다운로드 및 파싱 - wget.download
- 2020/11/23 - [Python과 머신러닝/웹 데이터 추출] - [Python.Web] BeautifulSoup과 wget 으로 웹크롤링, 데이터 스크레이핑
- 2020/12/23 - [Python과 머신러닝/Pandas 데이터 분석] - [Python.Pandas] Groupby 함수 이해하기 - 1편
- 2020/12/24 - [Python과 머신러닝/Pandas 데이터 분석] - [Python.Pandas] Groupby 이해하기 - 2편
[Python.Web] wget으로 웹 데이터 다운로드 및 파싱 - wget.download
요약 한 웹사이트에서 여러 가지의 파일을 다운로드하고 싶을 때에, wget을 사용하여 한번에 다운 받는 프로그램을 짤 수 있다 이전에 정리한 내용에 이어서, 정규식을 사용하여 원하는 파일을
coding-grandpa.tistory.com
[Python.Web] BeautifulSoup과 wget 으로 웹크롤링, 데이터 스크레이핑
요약 지난 내용은 다운로드하여놓은 xml파일을 분석했다면, 이번엔 웹에서 다운로드하는 단계까지 자동화한다 BeautifulSoup으로 하는 웹크롤링, 데이터 스크레이핑 요약 XML이란 eXtensible Markup Languag
coding-grandpa.tistory.com
[Python.Pandas] Groupby 함수 이해하기 - 1편
1. Groupby 란? GroupBy란, 주어진 데이터를 그룹 별로 구분하여 데이터를 보기 위해 사용되는 함수이다. SQL을 해본 사람이라면 SQL의 Groupby와 동일한 동작을 하는 함수이다. Excel의 Pivot Table과도 유사
coding-grandpa.tistory.com
[Python.Pandas] Groupby 이해하기 - 2편
0. 이전 포스트 2020/12/23 - [Python과 머신러닝/Pandas 데이터 분석] - [Python.Pandas] Groupby 함수 이해하기 - 1편 [Python.Pandas] Groupby 함수 이해하기 - 1편 1. Groupby 란? GroupBy란, 주어진 데이터를..
coding-grandpa.tistory.com
1. Read_CSV를 통해 데이터를 읽어 들이면, 시간 관련 변수는 object type data로 읽힌다.
In [1]:import wget
import pandas as pd
import numpy as np
import dateutil
In [2]:url = 'https://www.shanelynn.ie/wp-content/uploads/2015/06/phone_data.csv'
wget.download(url)
100% [..............................................................................] 40576 / 40576
Out[2]:'phone_data.csv'
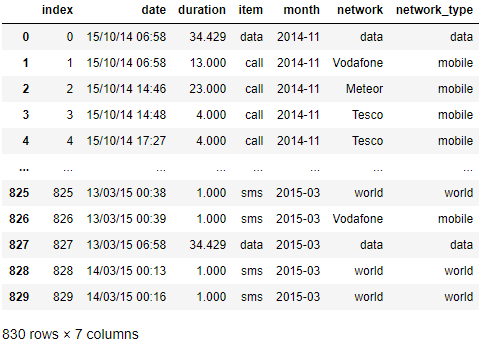
In [3]:df_phone = pd.read_csv('./phone_data.csv')
df_phone
Out[3]:
In [4]:df_phone.dtypes
Out[4]:index int64
date object
duration float64
item object
month object
network object
network_type object
dtype: object
- 어떤 데이터를 분석해도 날짜/시간 등의 시간 데이터는 항상 필요한데, read_csv를 통해 읽어들이면 object 타입의 데이터로 읽어 들이게 된다.
- In[4]와 같이 df_phone.dtypes property를 읽어보면, 각 Series의 타입을 볼 수 있는데, date는 object (별 특징이 없는 데이터 타입)이라는 것을 알 수 있다.
- object 타입의 변수를 직접 파싱 해서 분석할 수도 있지만, 가성비가 너무 떨어지는 작업이다.
- dateutil 라이브러리를 활용해서 데이터 전처리를 수행해보자.
- 본 데이터는 통화 / 문자 / 데이터 사용량, 시간, 통신사 등을 정리한 데이터이고, 위 코드의 링크에서 누구나 다운로드 할 수 있는 데이터이다.
2. dateutil 라이브러리를 사용한 Date/Time Series 전처리
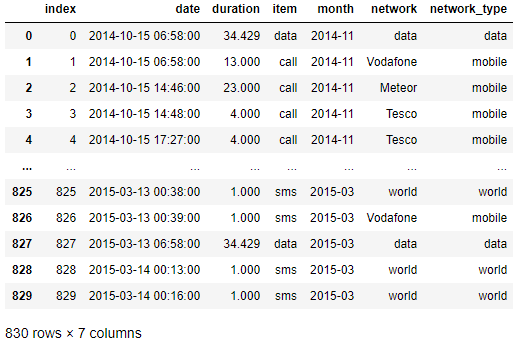
In [5]:df_phone['date'] = df_phone['date'].apply(dateutil.parser.parse, dayfirst=True) # date parsing df_phone
Out[5]:
In [6]:df_phone.dtypes
Out[6]:index int64
date datetime64[ns]
duration float64
item object
month object
network object
network_type object
dtype: object
- In[5]의 .apply 함수를 통해서 dateutil.parser.parse를 적용하면, 일반 object 타입의 Series를 datetime 타입의 데이터로 변형할 수 있다.
- Out[5]의 출력 값도 달라지고, Out[6]의 dtypes의 결과물도 달라졌다는 것을 확인할 수 있다.
3. 월별 데이터 출력하기
In [7]:df_phone.groupby('month')['duration'].sum()
Out[7]:month 2014-11 26639.441
2014-12 14641.870
2015-01 18223.299
2015-02 15522.299
2015-03 22750.441
Name: duration, dtype: float64
In [8]:df_phone.groupby('month')['duration'].sum().plot()
Out[8]: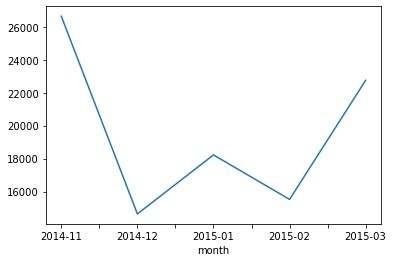
4. 월별 / 항목별 데이터 분석하기
In [9]:df_phone[df_phone['item'] == 'call'].groupby('month')['duration'].sum()
Out[9]: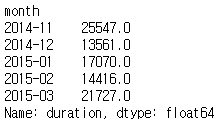
In [10]:df_phone[df_phone['item'] == 'call'].groupby('month')['duration'].sum().plot()
Out[10]: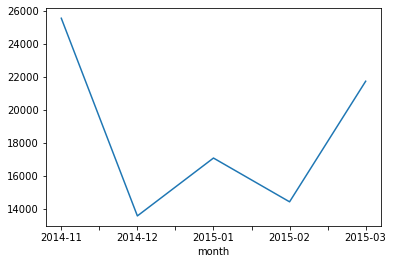
- Fancy indexing과 groupby를 같이 활용하면 위와 같이 각 type별 정보를 추출할 수 있다.
- 위 데이터는 월별 통화량의 총합과 데이터를 그린 것이다.
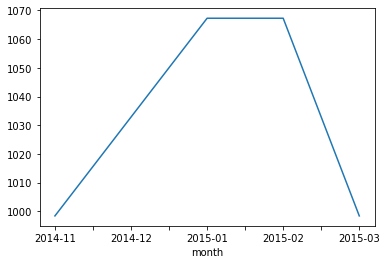
- 문자와 데이터 사용량도 아래와 같이 볼 수 있다.
In [11]:df_phone[df_phone['item'] == 'data'].groupby('month')['duration'].sum().plot()
Out[11]:
In [12]:df_phone[df_phone['item'] == 'sms'].groupby('month')['duration'].sum().plot()
Out[12]: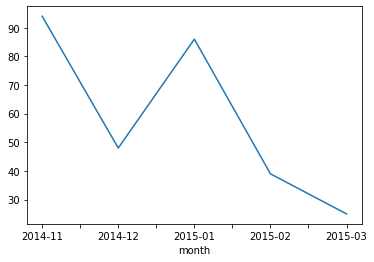
5. 월별 / 항목별 데이터 [한 번에] 분석하기
In [13]:df_phone.groupby(['month', 'item'])['duration'].sum()
Out[13]: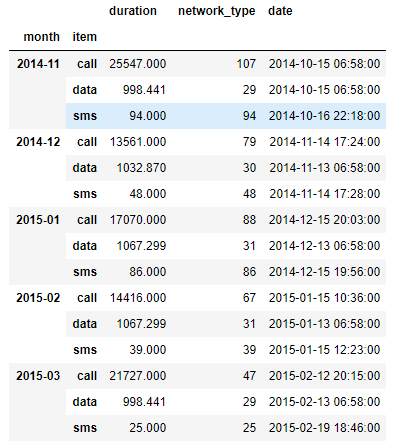
- 4번과 같이 따로 정리할 수도 있지만, 이렇게 되면 항목이 추가될 때마다 코드도 수정이 필요하기 때문에 유지보수 측면에서 매우 불편하고, 사실상 자동화된 분석이 불가능하다고 봐야 한다.
- 지난 포스트에서 정리했던 이중 GroupBy를 사용하면 한 번에 모든 item에 대한 사용량을 정리할 수 있다.
- In[13]과 같이 적는다면, 중간에 item이 추가되어도 동일 코드로 분석이 가능하다.
- 이를 그래프로 그리려면 다음과 같이 나올 수 있다.
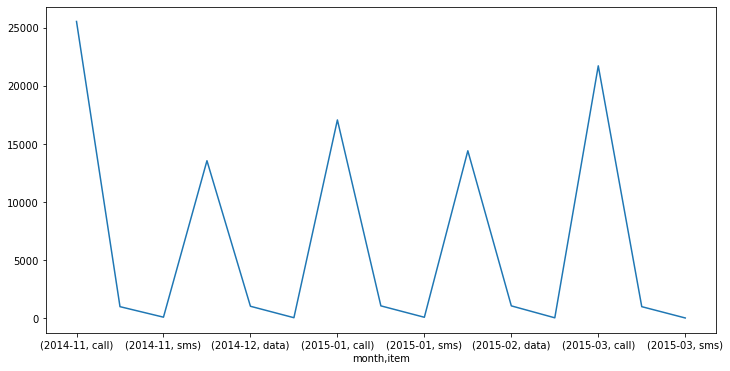
In [14]:df_phone.groupby(['month', 'item'])['duration'].sum().plot(figsize=(12,6))
Out[14]:
6. 월별 / 항목별 데이터 [진짜 한 번에] 분석하기
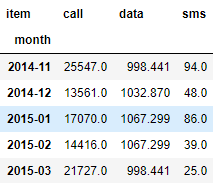
In [15]:df_phone.groupby(['month', 'item'])['duration'].sum().unstack()
Out[15]:
In [16]:df_phone.groupby(['month', 'item'])['duration'].sum().unstack().plot()
Out[16]: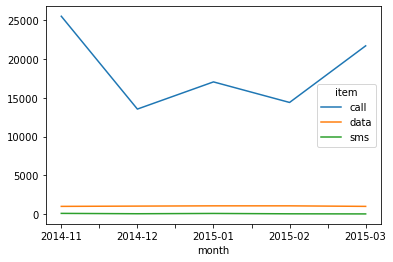
- 많은 사람들이 겪는 시행착오를 동일하게 정리하다 보니 말이 길어졌는데, 진짜 한 번에 하려면 unstack을 해서 보면 가장 편하다. (Unstack에 대해서도 지난 포스트에서 정리했다.)
- 5단계에서 정리한 그래프는 사실 별 의미가 없다. 그래프를 봐도 통신량의 비교가 사실상 무의미한데, 이를 unstack 하면 위 Out[16]과 같은 그래프가 나오고, 위 데이터는 2014년이라 그런지 통화량이 월등히 많고, 문자는 거의 없다는 것을 확인할 수 있다.
7. Series 별로 다른 데이터를 분석하려면
In [17]:df_phone.groupby(['month', 'item']).agg({'duration':sum,# find the sum of the durations for each group
'network_type':'count', #find the number of network types
'date':'first'}) # find the first date per group
Out[17]:
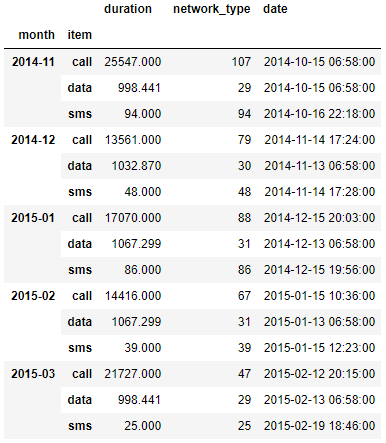
- 6단계까지 잘 수행했다면 총합을 잘 확인할 수 있게 되었다.
- 하지만 Series별로 총합이 아닌 서로 다른 통계 데이터를 보고 싶다면 어떻게 해야 할까?
- 예를 들어 duration은 기존처럼 sum을 보는 것이 의미가 있겠지만, network_type이나 date은 sum을 보는 것이 아무런 통계적 의미가 없다.
- network_type의 개수를 알고 싶고, date 중 가장 앞선 날짜를 알고 싶다면, groupby 이후에 .agg function으로 각 column 별로 다른 기준을 지정해주면 된다.
- In[17]을 보면 Groupby까지는 동일하고, .agg에서 각 column별로 원하는 기준을 dict type으로 전달해주면 된다.
- 그 결과 Out[17] 같이 Series 별로 다른 값을 한 DataFrame으로 볼 수 있도록 나온다.
8. 여러 기준으로 agg함수 수행하기
In [18]:df_phone.groupby(['month', 'item']).agg({'duration':[min, max, sum],# find the min, max, sum of the duration
'network_type':'count', # find the number of network types
'date':[min, 'first', 'nunique']}) # find the min, first, and number of unique dates
Out[18]:
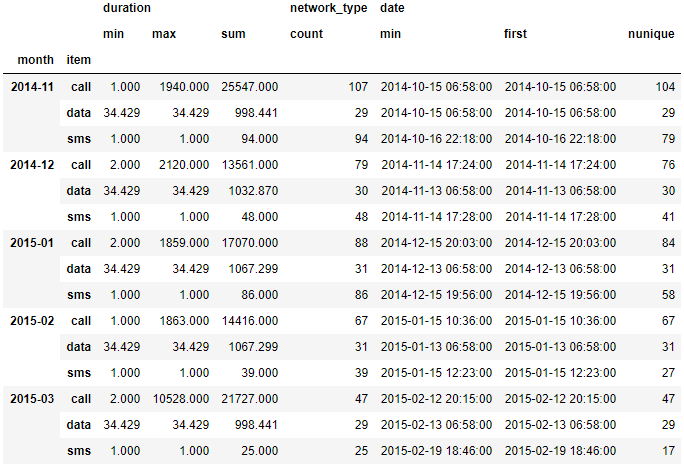
- 7단계에서는 각 Series 별로 서로 다른 기준의 통계 데이터를 추출하는 방법을 정리했다.
- 8단계에서는 각 Series 내에서도 여러 기준의 통계 데이터를 추출하는 코드를 정리한 것이다.
- 결론부터 얘기하면 각 column 별로 list 형태의 기준을 전달하면 된다.
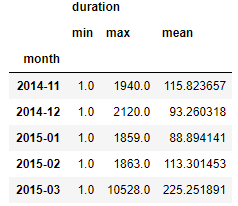
9. Grouping 이후 column index 수정하기
In [19]:grouped = df_phone.groupby('month').agg({'duration':[min,max, np.mean]})
grouped
Out[19]:
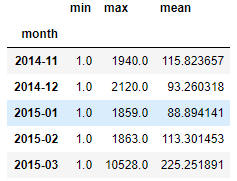
In [20]:grouped.columns = grouped.columns.droplevel(level=0)
grouped
Out[20]:
In [21]:grouped.rename(columns = {'min':'min_duration',
'max':'max_duration',
'mean':'mean_duration'})
Out[21]: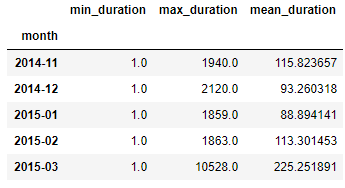
- Grouping을 하고 나면, 불필요한 level은 제거해주는 것이 가독성에 도움이 된다.
- In[20]의 columns.droplevel을 통해 불필요한 변수는 제거한다.
- In[21]의 .rename함수를 통해 column의 이름을 바꿔줄 수 있고, 이렇게 하면 2개의 level이 있는 것보다 훨씬 가독성이 좋고 분석도 수월하다.
'Python과 머신러닝 > Pandas 데이터 분석' 카테고리의 다른 글
| [Python.Pandas] Merge 와 Concat 하여 데이터 붙이기 (0) | 2020.12.29 |
|---|---|
| [Python.Pandas] Pivot Table과 CrossTab 사용하기 (0) | 2020.12.28 |
| [Python.Pandas] Groupby 이해하기 - 2편 (0) | 2020.12.24 |
| [Python.Pandas] Groupby 함수 이해하기 - 1편 (0) | 2020.12.23 |
| [Python.Pandas] Built-in Function 이해하기 - .describe() (0) | 2020.12.22 |