[Python.ML] Pandas로 데이터 불러오기
2020. 11. 30. 11:00ㆍPython과 머신러닝/웹 데이터 추출
0. 요약
- Pandas란 무엇이고, Pandas를 통해 어떤 데이터를 읽어 들일 수 있는지 보려고 한다.
- 실제 예제를 통해서 어떻게 csv 형태의 데이터를 읽어 들일 수 있는지도 볼 계획이다.
- 2020/11/27 - [Python과 머신러닝/웹 데이터 추출] - [Python.ML] Python & Machine Learning Overview
- 2020/11/28 - [Python과 머신러닝/웹 데이터 추출] - [Python.ML] Feature, 독립변수, input 값 알아보기
[Python.ML] Python & Machine Learning Overview
요약 Machine Learning을 쉽게 설명하면, 컴퓨터에게 무한반복의 학습을 통해 하나의 task를 잘하도록 교육하는 것이다. Machine Learning의 목적은 기존 데이터를 가지고 새로운 데이터의 결과를 예측하
coding-grandpa.tistory.com
[Python.ML] Feature, 독립변수, input 값 알아보기
Feature란? 머신러닝이란 결국 주어진 x값들에 대한 y값을 계산할 수 있는 하나의 함수 f를 찾는 것이다. Y라는 종속변수를 계산하기 위해 사용되는 input 값 혹은 독립변수를 우리는 하나의 Feature라
coding-grandpa.tistory.com
1. 용어 정리
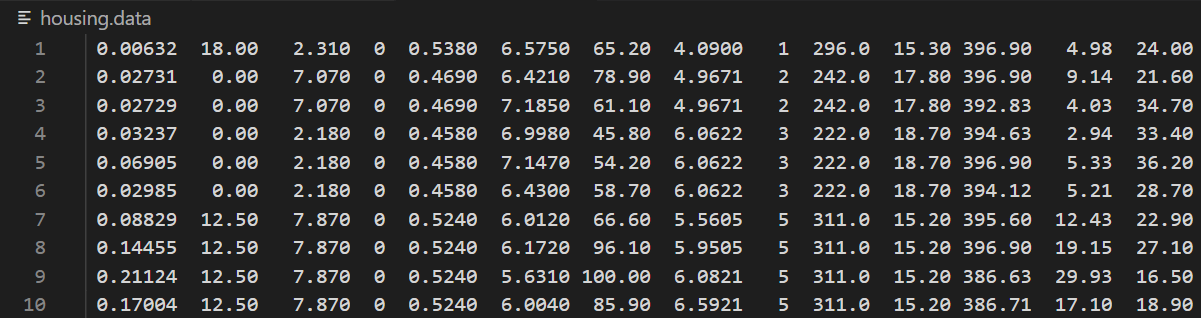
- 데이터 링크 : archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data
- 위 데이터와 같이 전체 데이터는 Data table/Sample/모판 이라는 용어로 불린다.
- 그중 한 Column을 Attribute/Feature/Field라고 한다(Attribute는 DB에서, Feature는 ML에서 주로 사용하는 용어).
- 그리고 데이터 한 줄은 Instance/Tuple/Row라고 한다.
- 한 줄의 한 column, 즉 하나의 데이터를 Data라고 칭한다.
2. 데이터 호출
- 데이터 분석 시 사용되는 raw data는 일반적으로 binary data가 아닌 text형태의 데이터이다.
- 주로 CSV, JSON, XML 등을 통해서 정보가 전달된다.
- 이러한 형태로 구조화된 데이터의 처리를 지원하는 라이브러리가 Pandas이다.
- Python계의 Excel이라고도 알려진 Pandas는 고성능 array 계산 라이브러리인 numpy와 같이 강력한 스프레드시트 처리 기능을 제공한다
- 인덱싱, 연산용 함수, 전처리 함수 등도 제공한다.
3. 데이터 호출 예제
import pandas as pd
data_url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data' # Data URL
df_data = pd.read_csv(data_url,
sep='\s+', # 여러 공간을 구분자로 지정. Text간 여러 space를 무시하고 데이터만 추출한다
header = None) # header는 지정하지 않는다.
df_data.head() # 데이터의 상위 5 row만 출력하여 데이터가 잘 읽혔는지 확인한다.- pandas library를 import한다 (설치가 되지 않았을 경우 pip install pandas를 통해 설치할 수 있다)
- data url을 변수에 담고,
- pd.read_csv 함수를 사용해서 data_url로부터 다운로드한 데이터를 읽어 들인다.
- 이때 구분자는 여러 space로 지정한다. 이유는 실제 데이터를 봤을 경우 하나의 공백으로 데이터가 구분되어있지 않고, 여러 공백들 (3개)로 구분되어있어서, 여러 공백임을 정규표현식으로 지정해준다.
- 그리고 이 데이터의 헤더는 따로 지정해주지 않는다.
- 마지막으로 df_data.head() 함수를 통해 데이터가 잘 읽혔는지 확인한다. head함수는 상위 5개의 row를 반환해주는 함수로 출력하여 직접 눈으로 검증할 수 있다.
마무리
- Pandas는 여러 형태의 데이터를 읽어 들일 수 있는 기능을 제공하고, excel과 유사한 대부분의 기능을 제공하는
강력한 라이브러리이다. - 이를 통해 데이터를 읽어오는 예제를 보았고, 다음 포스트에서는 데이터 처리까지 보고자 한다.
'Python과 머신러닝 > 웹 데이터 추출' 카테고리의 다른 글
| [Python.ML] Feature, 독립변수, input 값 알아보기 (0) | 2020.11.28 |
|---|---|
| [Python.ML] Python & Machine Learning Overview (0) | 2020.11.27 |
| [Python.JSON] Python으로 JSON 데이터 저장 및 전달 - 실전편 (0) | 2020.11.26 |
| [Python.JSON] Python으로 JSON 데이터 읽기 - 실전편 (0) | 2020.11.25 |
| [Python.JSON] Python으로 JSON 데이터 파싱 - 이론편 (0) | 2020.11.24 |