[Python.Seaborn] Predefined Plots 2 - PointPlot, RegPlot, subplots
2021. 2. 10. 05:00ㆍPython과 머신러닝/MatPlotLib 데이터 시각화
0. 이전 포스트
1. Point Plot
In [11]:fig = plt.figure()
ax = sns.pointplot(x='time', y='total_bill', data=tips)

- Point Plot을 통해 점심 저녁의 평균값과 분포를 확인할 수 있다.
- 중간점이 각 점심/저녁 시간대의 평균 총비용을 가리키고, 수직선은 각 분포를 표현하는 그래프이다.
- 점심이 평균적으로 저녁보다 저렴하고, 저녁 메뉴는 총비용의 분포도가 더 적다는 것을 알 수 있다.
2. RegPlot
In [13]:fig = plt.figure()
ax = sns.regplot(x='total_bill', y='tip', data=tips)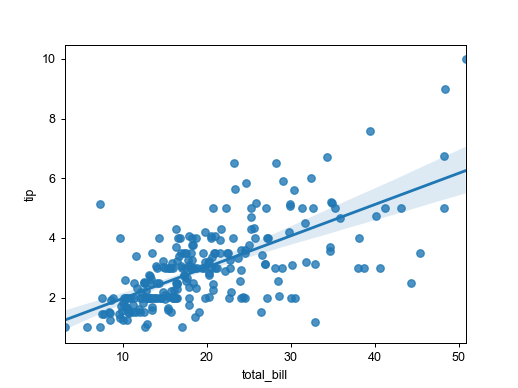
- RegPlot은 Regression Plot의 약자이다.
- 데이터의 분포와, 이 데이터를 선형으로 표현하는 Regression Line을 동시에 표현해주는 그래프이다.
- 주식 데이터 분석, 추세 그리기 등의 기본은 RegPlot으로부터 시작된다.
3. RegPlot - Category 데이터
In [14]:fig = plt.figure()
ax=sns.regplot(x='size',
y='total_bill',
data=tips,
x_estimator=np.mean)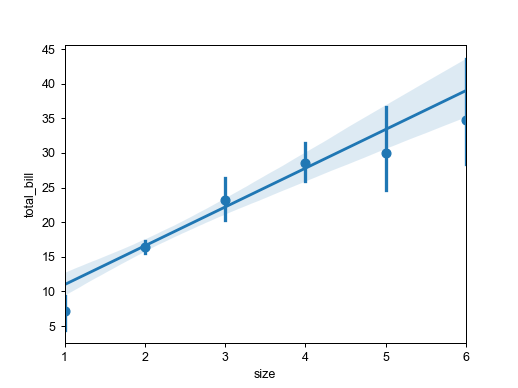
- RegPlot의 X축이 Category 데이터일 때에도, RegPlot은 정상적으로 그려진다.
- 위 예제 코드는 각 Category 별 평균값을 점으로, 분포를 수직선으로 표현하고 있다.
- 평균값/분포를 통해 Y축의 값과의 선형 관계를 표현하고, 동일하게 regression line을 보여줘서,
Category 변수의 관계성을 보고싶을 때에도 유용하게 사용되는 그래프이다.
4. Subplot을 활용해서 다양한 그래프 한 번에 비교하기
# 초기 설정
In [16]:sns.set(style = 'white', palette='muted', color_codes=True)
sns.despine(left=True)
In [17]:rs = np.random.RandomState(10)
d=rs.normal(size=100)
In [18]:f, axes = plt.subplots(2,2,figsize=(7,7), sharex=True)
- Subplot이란 하나의 도화지를 여러 구획을 나눠서 그림을 그리는 것과 유사하다고 MatPlotLib을 공부할 때도 봤다.
- In[16]은 sns를 기본적으로 설정하기 위한 style, palette, color code 등을 지정한다
- 여기서 처음 보는 함수는 sns.despine(left=True)이다
- 아무런 Parameter가 없을 때는 X축/Y축에 해당하는 왼쪽, 아랫쪽 선을 실선만 그려주는 함수이다.
- 여기에 left=True는 '왼쪽의 수직선(Y축)도 지워달라'는 Parameter이기 때문에 아래의 그림처럼
각 그래프들의 X축 선들만 그려지게 된다. - 반대로 Y축만 남기고 X축의 선들을 지우고 싶을 때는 bottom=True를 사용하면 된다.
- left=True, bottom=True를 하면 아무런 선이 없는 그래프를 표현할 수 있다.
- In [17]은 Random 한 값을 생성하는 RandomState 객체를 rs라는 변수로 생성한다.
- d=rs.normal(size=100)이란 '정규분포의 random한 값 100개를 뽑아달라'는 의미가 된다.
- In[18] : f, axes = plt.subplots(2,2,figsize=(7,7), sharex=True)
- 2,2 : 2x2의 grid 형태로 subplot을 만들어 달라
- figsize =(7,7) : 전체 figure size는 7 x 7
- sharex=True : 여러 row의 그래프가 존재한다면, 모든 row가 X축을 공유한다는 의미이다.
(즉, 최 하단에 X에 대한 값을 한 번만 띄우고, 그 외의 row들에는 X값을 표기하지 않는다)
- 이렇게 도화지 준비작업이 끝났고, 이제는 각 subplot을 채우는 동작만 남았다.
In [19]:sns.distplot(d, color='m', ax=axes[0,0])
In [20]:sns.distplot(d, kde=False, color='b', ax=axes[0,1])
In [21]:sns.distplot(d, hist=False, color='r', rug=True, ax=axes[1,0])
In [22]:sns.distplot(d, hist=False, color='g', kde_kws={'shade':True}, ax=axes[1,1])
In [23]:plt.setp(axes, yticks=[]) #yticks 없애기
In [24]:plt.tight_layout()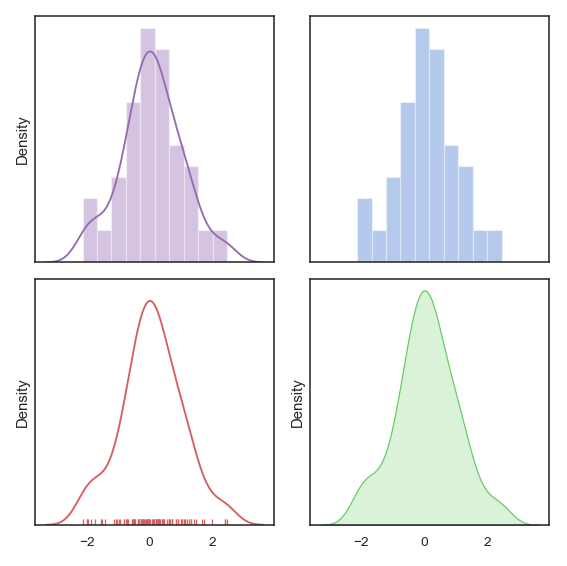
- In[19]~In[22] : 2x2의 subplot을 한 칸씩 채우는 코드이다.
- 기본 Parameter부터 정리해보자
- d : data (이 경우 정규분포를 따르는 random data 100개)
- color : 색깔
- ax : 데이터를 표현할 위치를 제공해준다. In[18]에서 axes 변수에 각 subplot을 담아왔으니,
이 중에서 원하는 위치를 index로 지정하여 전달하면 된다.
- 기본적으로 d/color/ax만 지정해주면 좌상단의 그래프처럼 histogram과 KDE (밀도) plot이 동시에 그려진다
- 여기에 kde=False 혹은 hist=False를 Parameter로 전달하면 각각이 제외되는 것을 확인할 수 있다.
- rug = True : 데이터의 위치를 나타내는 선분을 표시한다.
- kde_kws={'shade':True} : 분포 plot을 shade로 채워준다.
- 기본 Parameter부터 정리해보자
5. 관련 포스트
- 2021/02/11 - [Python과 머신러닝/MatPlotLib 데이터 시각화] - [Python.Seaborn] Predefined Plots 3 - Predefined Multiple Plots - RelPlot, CatPlot
- 2021/02/15 - [Python과 머신러닝/MatPlotLib 데이터 시각화] - [Python.Seaborn] Predefined Plots 4 - FacetGrid, Map, PairPlot, LMPlot
- 2021/02/21 - [Python과 머신러닝/MatPlotLib 데이터 시각화] - [Python.Seaborn] Predefined Plots 5 - Pair Plot과 LM Plot