[Python.Seaborn] Predefined Plots 3 - Predefined Multiple Plots - RelPlot, CatPlot
2021. 2. 11. 05:00ㆍPython과 머신러닝/MatPlotLib 데이터 시각화
0. 이전 포스트
- 2021/02/06 - [Python과 머신러닝/MatPlotLib 데이터 시각화] - [Python.Seaborn] Predefined Plots 1 - Box Plot, Violin Plot, Swarm Plot
- 2021/02/10 - [Python과 머신러닝/MatPlotLib 데이터 시각화] - [Python.Seaborn] Predefined Plots 2 - PointPlot, RegPlot, subplots
1. RelPlot - col='time' parameter 이해하기
In [25]:%matplotlib notebook
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
tips=sns.load_dataset('tips')
g = sns.relplot(x='total_bill',
y='tip',
hue='day',
col='time',
data=tips,
height=3)
- RelPlot은 관계/분포를 볼 수 있는 그래프라서 이전 포스트에서 정리한 내용들과 크게 다르지 않다.
- x, y, hue는 각각 x축의 데이터, y축의 데이터, 그리고 각 데이터를 구분하기 위한 category 변수 hue이다.
- 여기서의 가장 큰 차이는 col='time' parameter 일 것이다.
- Column별로 다른 time의 데이터를 보여달라는 의미가 된다.
- 그래서 위 데이터에서 보다시피 Lunch의 TotalBill vs Tip의 데이터와 Dinner의 데이터를 따로 구분해서 볼 수 있게 된다.
2. RelPlot - Row/Col 둘 다 사용하기
In [26]:g = sns.relplot(x='total_bill',
y='tip',
hue='day',
col='time',
row='sex',
data=tips,
height=3)

- 두 가지의 category 변수로 구분해서 보고 싶으면 row/col을 둘 다 지정해서 비교할 수 있다.
- 이 경우 row별로 성별을 구분했고, col별로 time을 구분했다.
- 이 데이터를 통해서 알 수 있는 건, 일반적인 분포는 남녀 간의 차이가 많지 않았지만,
남자가 대체로 더 비싼 식사를 지불했던 outlier가 많았던 것처럼 보인다. - 이와 같이 category 별로 데이터를 따로 분류해서 볼 수 있는 것이 RelPlot의 가장 큰 장점이다.
3. RelPlot - Size
In [27]:g = sns.relplot(x='total_bill',
y='tip',
hue='time',
size='size',
palette=['b', 'r'],
sizes=(5,100),
col='time',
data=tips)
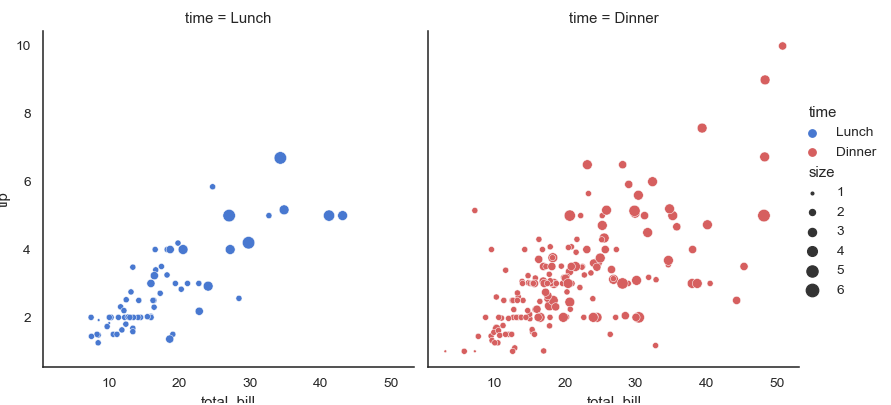
- size='size'
- tips 데이터를 자세히 보면 'size'라는 column은 횟수를 의미한다.
- 즉, 해당 Tip과 TotalBill을 지불한 count를 세어 놓은 값이다.
- 이를 size parameter로 전달하여 더 빈번한 경우를 큰 원으로 표현할 수 있다.
- size를 사용하지 않는다면 아무리 많아다 한 점이 겹쳐 보여서 빈도를 파악하기 어렵기 때문에,
size를 사용해서 case별 분포를 표현할 뿐만 아니라 count도 한 번에 비교할 수 있다.
4. RelPlot - 선형 그래프
In [28]:fmri=sns.load_dataset('fmri')
g = sns.relplot(x='timepoint',
y='signal',
hue='event',
style='event',
col='region',
kind='line',
data=fmri)
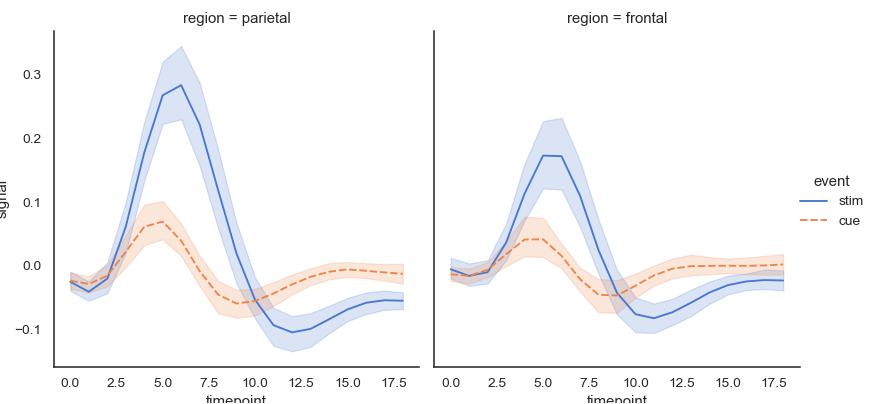
- kind='line'을 추가하면 기존의 분포도 그래프가 아닌 선형 그래프로 표현할 수 있다.
- 선형 그래프를 표현하면, 각 지점에서의 range와 평균값이 저절로 표현되어 실선/점선과 shade영역으로 구분해서 볼 수 있다.
- col과 hue parameter를 통해서 구분할 수 있는 것은 위와 동일하다.
5. CatPlot - 기본 분포 그래프
In [29]:exercise = sns.load_dataset('exercise')
In [30]:g = sns.catplot(x='time', y='pulse', hue='kind', data=exercise)
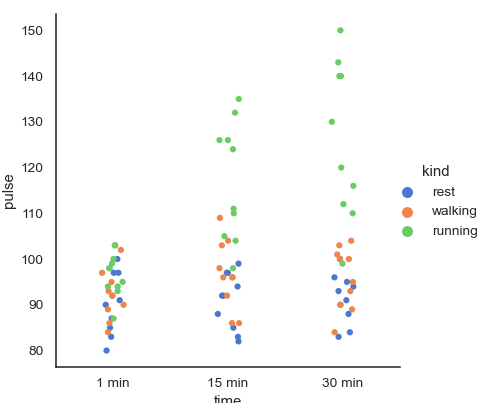
- CatPlot은 Category Plot의 약자로, X축에 Category Data를 입력하여 분포도를 비교할 때 사용된다.
- 그래서 x='time'으로 구분하였고, 위 그래프는 1분/15분/30분 운동을 했을 때의 심박수를 그래프로 그렸고,
- hue를 운동 종류로 지정하여 휴식/걷기/달리기 운동을 할 때의 심박수를 색깔별로 구분했다.
6. CatPlot - Violin plot
In [31]:g = sns.catplot(x='time', y='pulse', hue='kind', data=exercise, kind='violin')

- kind='violin' 을 지정하면 동일한 데이터를 바이올린 형태로 그릴 수 있다.
- 이렇게 했을 때의 장점은, hue별 구분이 조금 더 명확해진다는 점이다.
- 그래서 운동 시간이 늘어날수록 running의 분포는 넓게 퍼진다는 것을 볼 수 있고,
- 각 운동 종류별 분포도도 한 번에 확인할 수 있다.
7. Cat Plot - Count Plot 등으로 보기
In [32]:titanic = sns.load_dataset('titanic')
g=sns.catplot('alive',
col='deck',
col_wrap=4,
data=titanic[titanic.deck.notnull()],
kind='count',
height=2.5,
aspect=.8)
- 이전에는 Cat Plot을 가장 기본적인 분포도를 봤다면, kind='count'로 수정하여 histogram처럼 비교할 수 있다.
- alive에 대한 count plot을 각 deck별로 그리고, 한 row에 4개씩만 표현되도록 catplot을 그리라는 명령어이다.